Tatsunori Hashimoto
Assistant Professor, Stanford
thashim [AT] stanford.edu
Diversity and coverage in natural language generation
Ensuring models do not merely plagiarize the training set
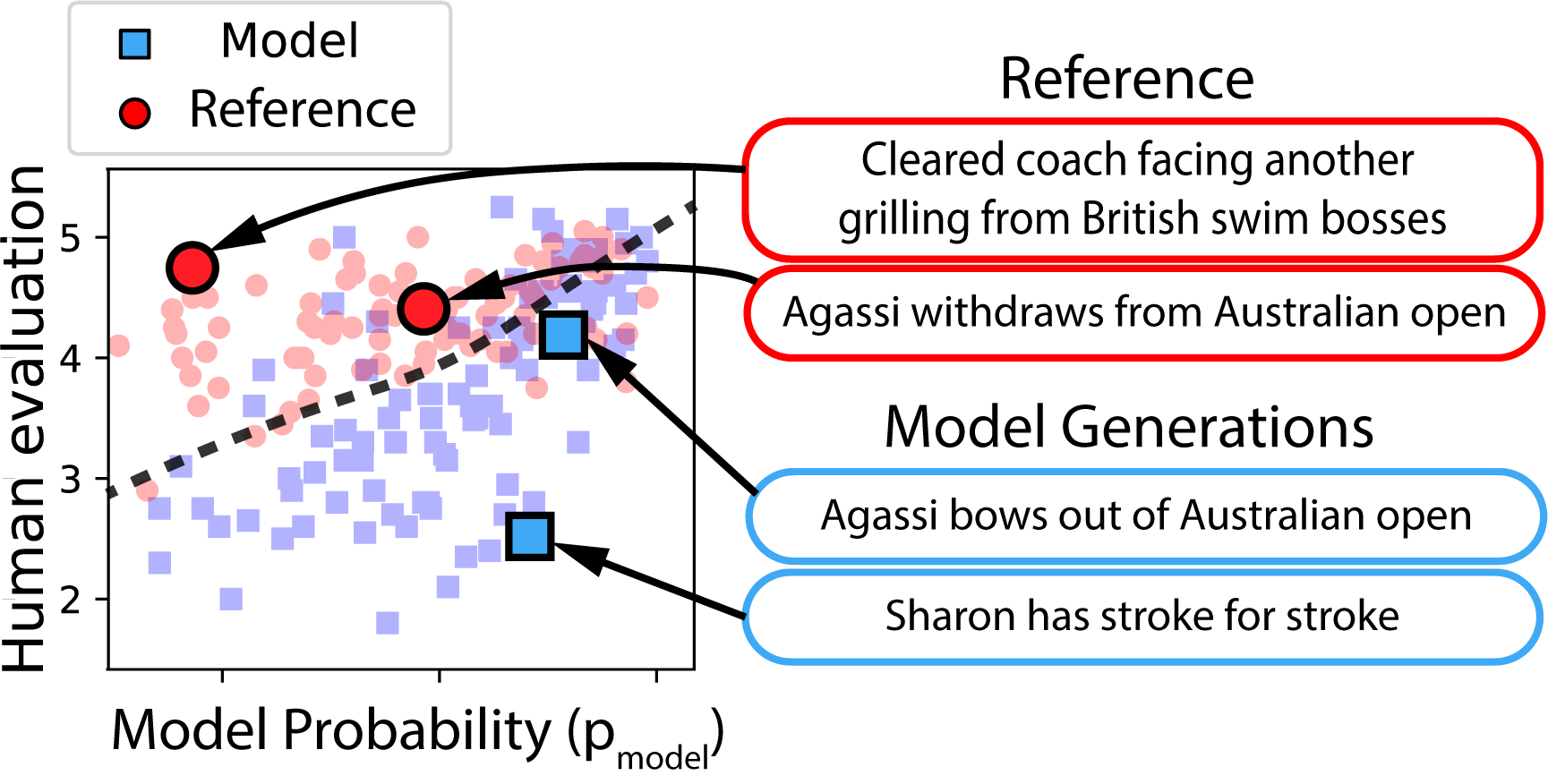 Overview:
Recent progress in generative models for images and text have shown that carefully constructed neural models
can generate samples which humans cannot distinguish from the original training data. However, it has been widely observed that these improvements in sample quality have come at the cost of ignoring atypical samples. For example, generative model for images trained on the handwritten digits {0, 1, .. 9} will learn to generate the most common digits in high resolution, and ignore the rest. Similarly, generative models for dialogue systems have the generic utterance problem of responding with ``I don’t know’’ whenever possible. In both cases, the focus on average quality – as measured by human evaluations – has resulted in generative models which systematically ignore atypical examples to improve average sample quality.
Overview:
Recent progress in generative models for images and text have shown that carefully constructed neural models
can generate samples which humans cannot distinguish from the original training data. However, it has been widely observed that these improvements in sample quality have come at the cost of ignoring atypical samples. For example, generative model for images trained on the handwritten digits {0, 1, .. 9} will learn to generate the most common digits in high resolution, and ignore the rest. Similarly, generative models for dialogue systems have the generic utterance problem of responding with ``I don’t know’’ whenever possible. In both cases, the focus on average quality – as measured by human evaluations – has resulted in generative models which systematically ignore atypical examples to improve average sample quality.
My work develops evaluations, models, and training procedures which ensure that a model has learned full diversity of utterances from the reference distribution.
In evaluation, we propose new evaluation for natural language generation (NLG) which leverages human sample quality judgments to estimate the total variation distance between a model and the reference distribution. Applying this evaluation to state-of-the-art models demonstrates a pervasive trade-off between the sample quality of neural NLG systems, and memorization of the training set [Hashimoto+ 2019].
In modeling and training, we have developed edit-based models, which learn to generate text by editing existing examples from the training set [Guu+ 2018]. We show that this method improves upon generation diversity and quality. When combined with a learned retrieval system, we show that such an edit system can match specialized code generation methods on code generation tasks [Hashimoto+ 2018].