Tatsunori Hashimoto
Assistant Professor, Stanford
thashim [AT] stanford.edu
Distributional Robustness for Uniform Performance
Making models perform uniformly over subpopulations
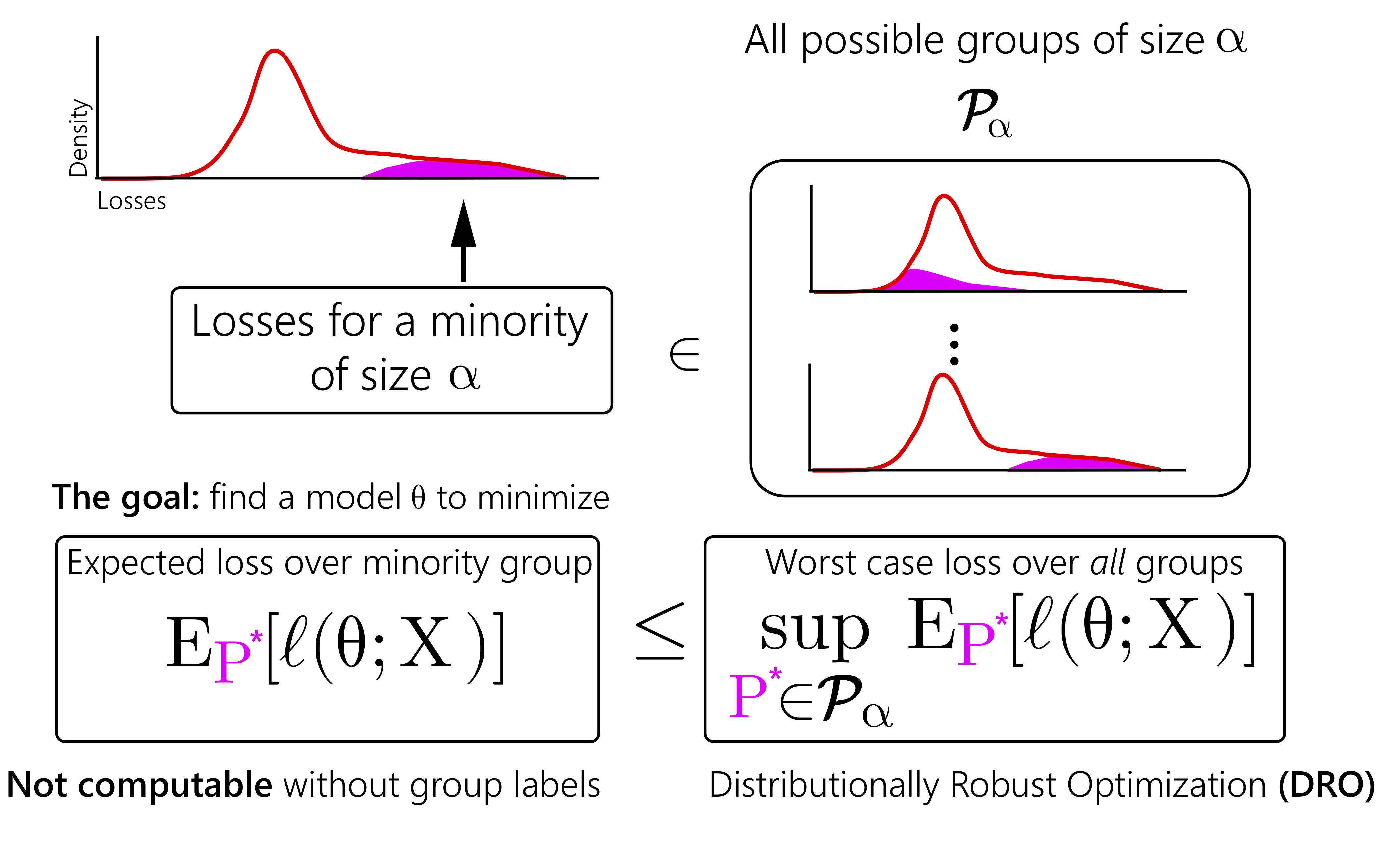 Overview:
Modern machine learning models are routinely trained over large, heterogeneous datasets consisting of many subpopulations, such as the different demographic groups in a loan default dataset.
Models which are accurate for one group may have high
error for other groups, and optimizing for average loss will select models which generally favor the majority group regardless of the quantity of data. This results in unfair and brittle models which systematically fail
on minority groups. When the group identity is known, we can explicitly optimize for the worst-off group, but this information is impractical to collect for many tasks due to cost or privacy concerns.
Overview:
Modern machine learning models are routinely trained over large, heterogeneous datasets consisting of many subpopulations, such as the different demographic groups in a loan default dataset.
Models which are accurate for one group may have high
error for other groups, and optimizing for average loss will select models which generally favor the majority group regardless of the quantity of data. This results in unfair and brittle models which systematically fail
on minority groups. When the group identity is known, we can explicitly optimize for the worst-off group, but this information is impractical to collect for many tasks due to cost or privacy concerns.
My work studies methods which ensure models perform well over all possible subpopulations of a certain size, as well as the implications of such a guarantee. I have derived an exact correspondence between uniform performance on all subpopulations and a distributionally robust optimization (DRO) problem [Duchi+ 2018] and regularization methods for effective solving such optimization problems at scale [Sagawa+ 2020, to appear at ICLR].
Using these techniques, we have built language models which performs well under substantial distribution shifts [Oren+ 2019] as well as training procedures which more fairly allocate a model’s predictive power to minority groups [Hashimoto+ 2018].